Single-Peaked Models#
Single-peaked preferences capture the idea that there exists a societal axis on which the candidates can be placed in such a way that the preferences of the voters are decreasing along both sides of the axis from their most preferred candidate.
- single_peaked_conitzer(num_voters: int, num_candidates: int, axis: list[int] = None, seed: int = None) list[list[int]][source]#
Generates ordinal votes that are single-peaked following the distribution defined by Conitzer (2009). The preferences generated are single-peaked with respect to the axis 0, 1, 2, …. Votes are generated uniformly at random as follows. The most preferred candidate (the peak) is selected uniformly at random. Then, either the candidate on the left, or the one on the right of the peak comes second in the ordering. Each case occurs with probability 0.5. The method is then iterated for the next left and right candidates (only one of them being different from before).
This method ensures that the probability for a given candidate to be the peak is uniform (as opposed to the method
single_peaked_walsh()). The probability for a single-peaked rank to be generated is equal to 1/m * (1/2)**dist_peak_to_end where m is the number of candidates and dist_peak_to_end is the minimum distance from to peak to an end of the axis (i.e., candidates 0 or m - 1).A collection of num_voters vote is generated independently and identically following the process described above.
- Parameters:
num_voters (int) – Number of Voters.
num_candidates (int) – Number of Candidates.
axis (list[int], default:
None) – The societal axisseed (int, default:
None) – Seed for numpy random number generator.
- Returns:
Ordinal votes.
- Return type:
list[list[int]]
Examples
from prefsampling.ordinal import single_peaked_conitzer # Sample a single-peaked profile via Conitzer's method with 2 voters and 3 candidates. single_peaked_conitzer(2, 3) # You can set the societal axis single_peaked_conitzer(2, 3, axis=[0, 2, 1]) # For reproducibility, you can set the seed. single_peaked_conitzer(2, 3, seed=1002)
Validation
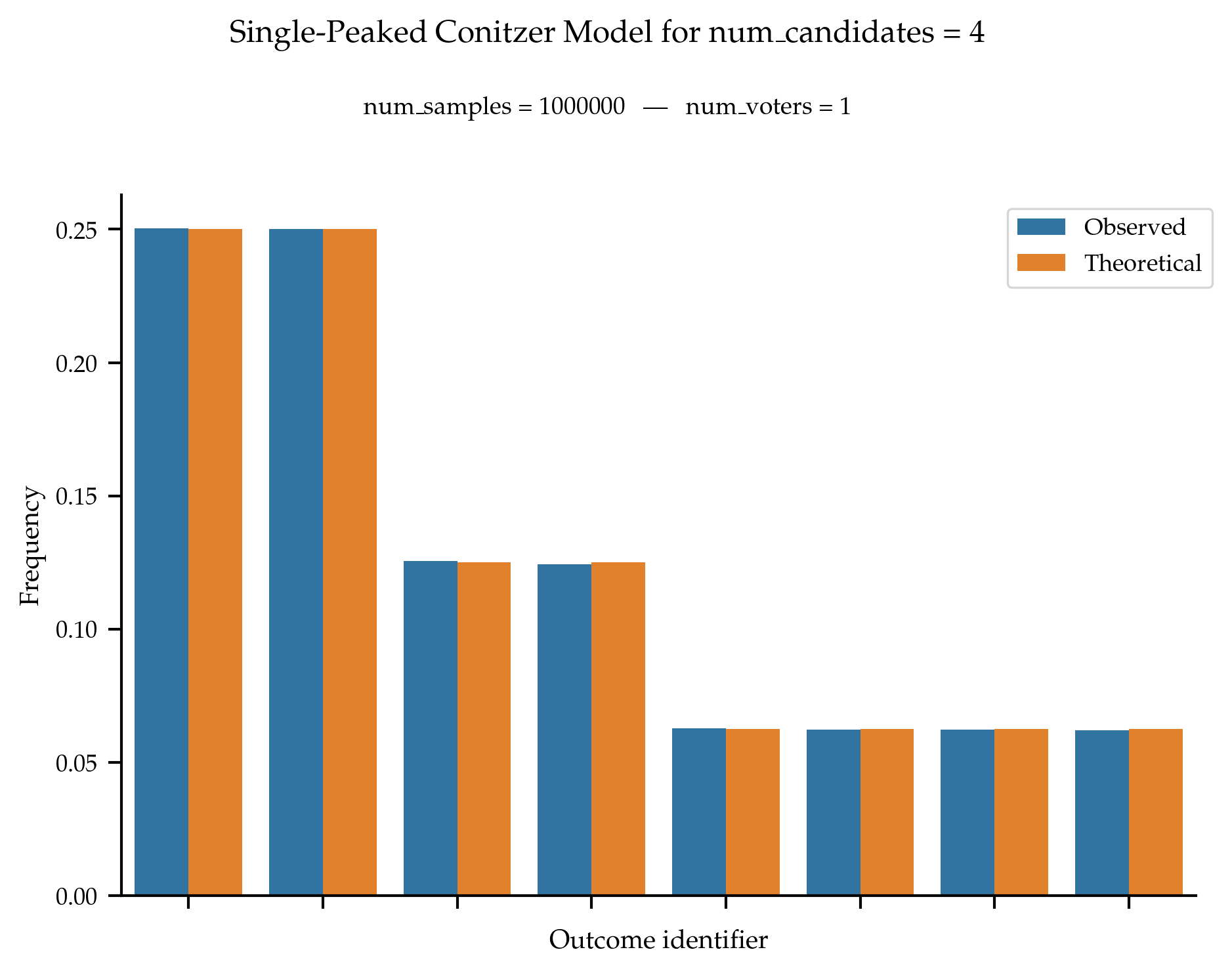
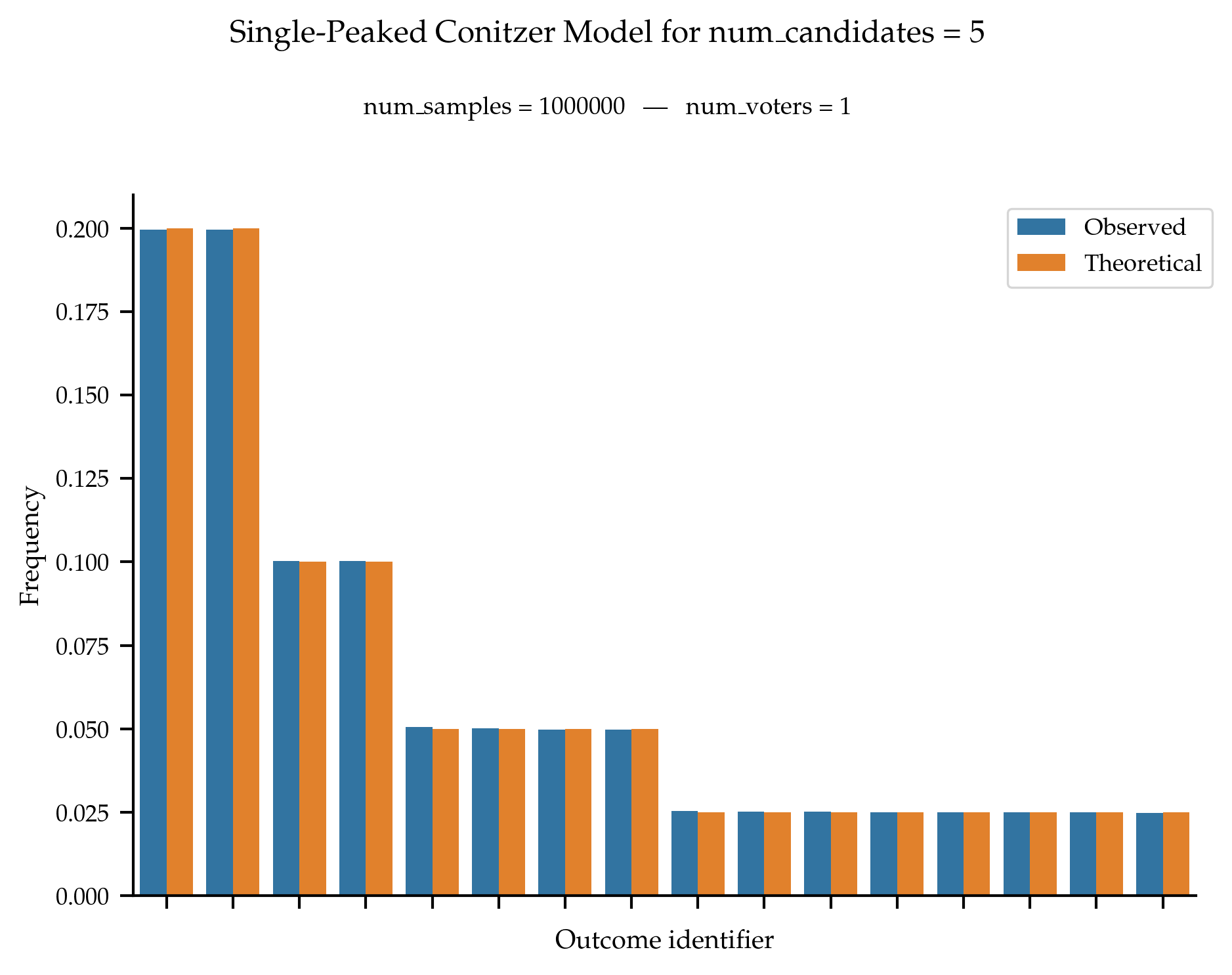
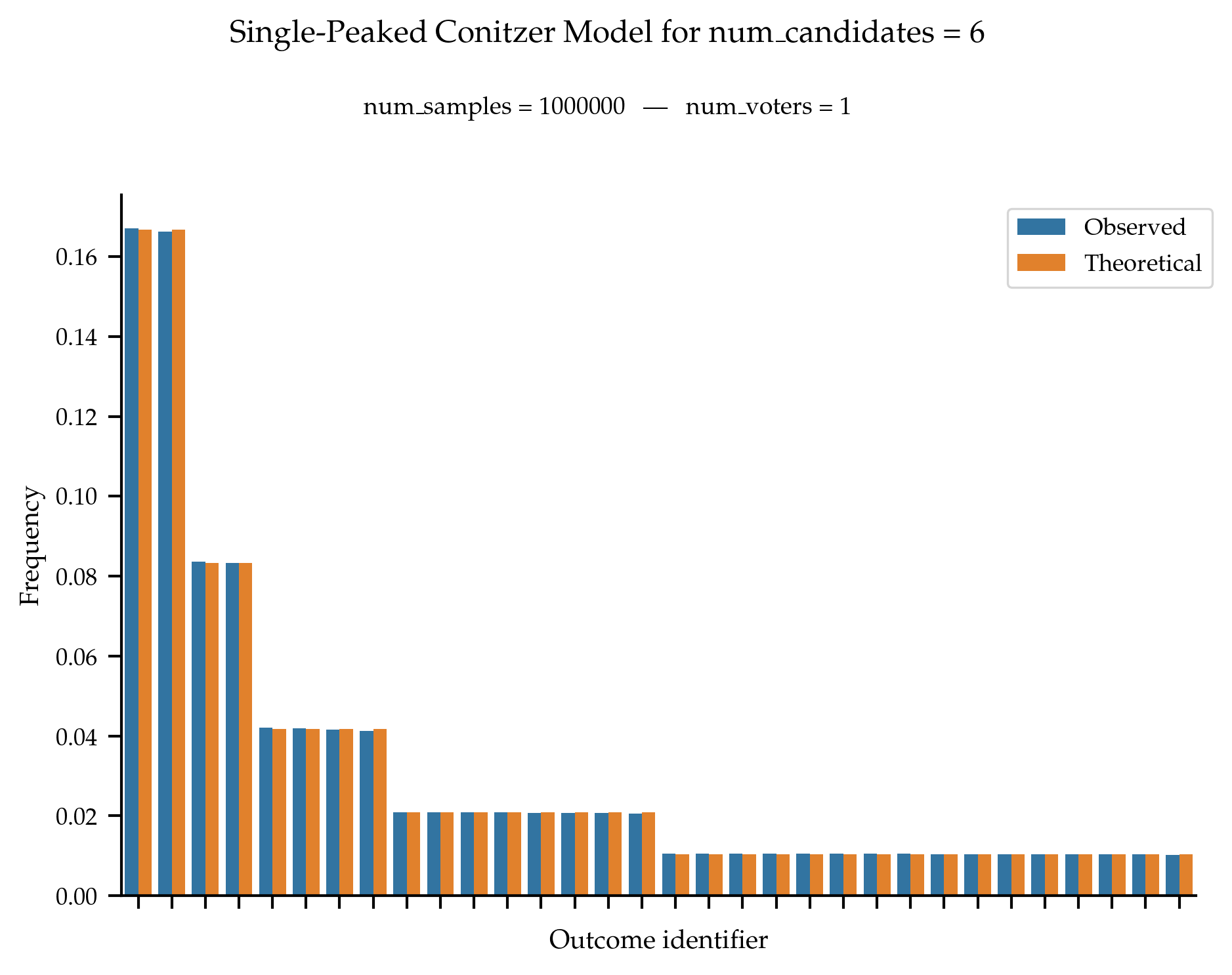
Following the method proposed by Contizer, the probability of observing a given single-peaked ranking (for a fixed axis) with m candidates is equal to:
\frac{1}{m} \times \left(\frac{1}{2}\right)^{\text{dist\_peak\_to\_end}}
where \text{dist\_peak\_to\_end} is the minimum distance from the top candidate to one of the end of the axis (i.e., candidates 0 or m - 1).
References
Eliciting single-peaked preferences using comparison queries, Vincent Conitzer, Journal of Artificial Intelligence Research, 35:161–191, 2009.
- single_peaked_walsh(num_voters: int, num_candidates: int, axis: list[int] = None, seed: int = None) list[list[int]][source]#
Generates ordinal votes that are single-peaked following the process described by Walsh (2015). The votes are generated from least preferred to most preferred candidates. A given position in the ordering is filled by selecting, with uniform probability, either the leftmost or the rightmost candidates that have not yet been positioned in the vote (left and right being defined by the axis 0, 1, 2, …).
A collection of num_voters vote is generated independently and identically following the process described above.
- Parameters:
num_voters (int) – Number of Voters.
num_candidates (int) – Number of Candidates.
axis (list[int], default:
None) – The societal axisseed (int, default:
None) – Seed for numpy random number generator.
- Returns:
Ordinal votes.
- Return type:
list[list[int]]
Examples
from prefsampling.ordinal import single_peaked_walsh # Sample a single-peaked profile via Walsh's method with 2 voters and 3 candidates. single_peaked_walsh(2, 3) # You can set the societal axis single_peaked_walsh(2, 3, axis=[0, 2, 1]) # For reproducibility, you can set the seed. single_peaked_walsh(2, 3, seed=1002)
Validation
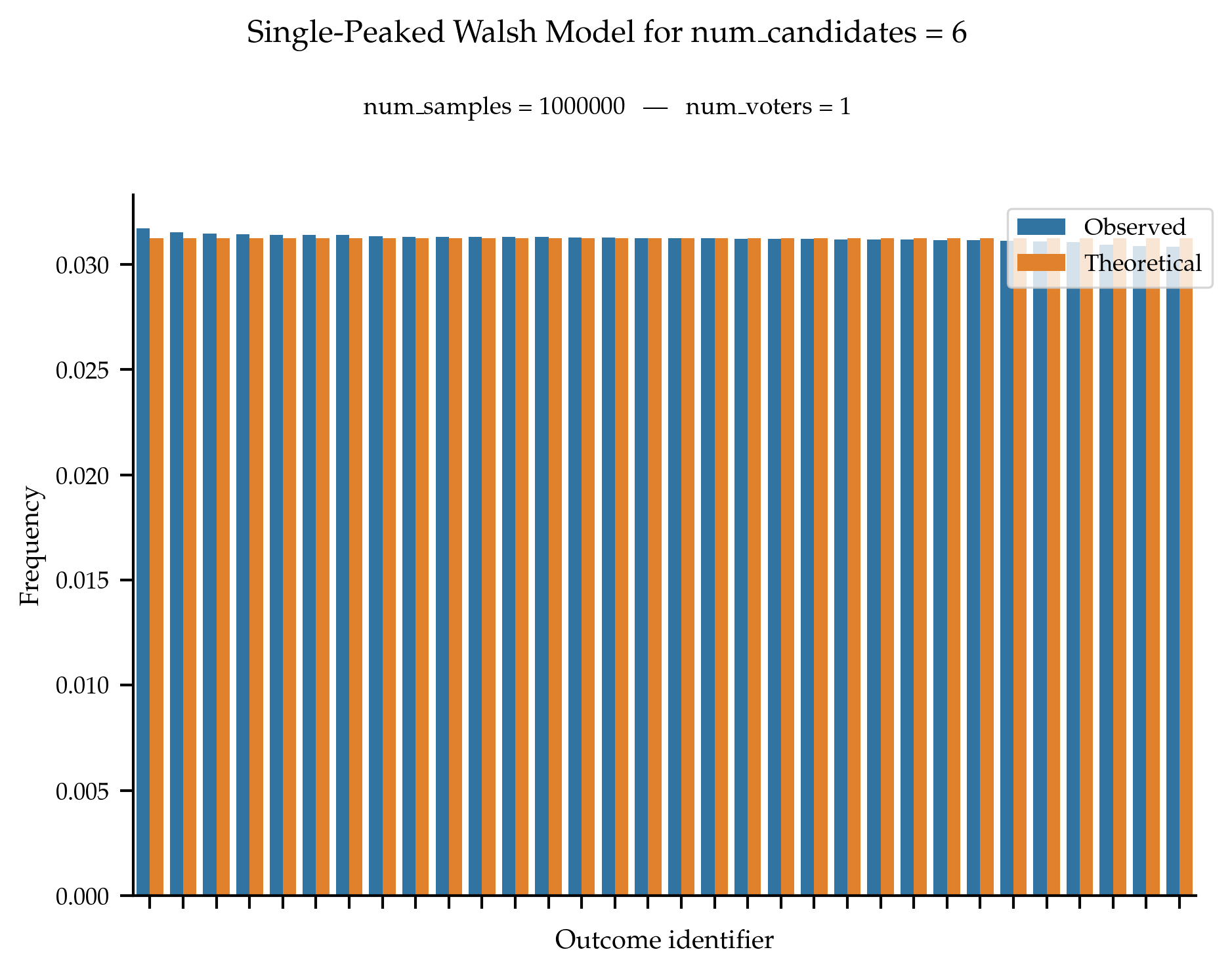
The method proposed by Walsh ensures that for a given axis, all single-peaked rankings are equally likely to be generated.


References
Generating Single Peaked Votes, Toby Walsh, ArXiV preprint, 2015.
- single_peaked_circle(num_voters: int, num_candidates: int, axis: list[int] = None, seed: int = None) list[list[int]][source]#
Generates ordinal votes that are single-peaked on a circle following a distribution inspired from the one by Conitzer (2009) for single-peakedness on a line (see
single_peaked_conitzer()). This method starts by determining the most preferred candidate (the peak). This is done with uniform probability over the candidates. Then, subsequent positions in the ordering are filled by taking either the next available candidate on the left or on the right, both cases occuring with probability 0.5. Left and right are defined here in terms of the circular axis: 0, 1, …, m, 1 (can be changed by using theaxisparameter).A collection of num_voters vote is generated independently and identically following the process described above.
- Parameters:
num_voters (int) – Number of Voters.
num_candidates (int) – Number of Candidates.
axis (list[int], default:
None) – The societal axisseed (int, default:
None) – Seed for numpy random number generator.
- Returns:
Ordinal votes.
- Return type:
list[list[int]]
Examples
from prefsampling.ordinal import single_peaked_circle # Sample a single-peaked on a circle profile with 2 voters and 3 candidates. single_peaked_circle(2, 3) # You can set the societal axis single_peaked_circle(2, 3, axis=[0, 2, 1]) # For reproducibility, you can set the seed. single_peaked_circle(2, 3, seed=1002)
Validation
The sampler for single-peaked on a circle is such that all single-peaked on a circle rankings are equally likely to be generated.
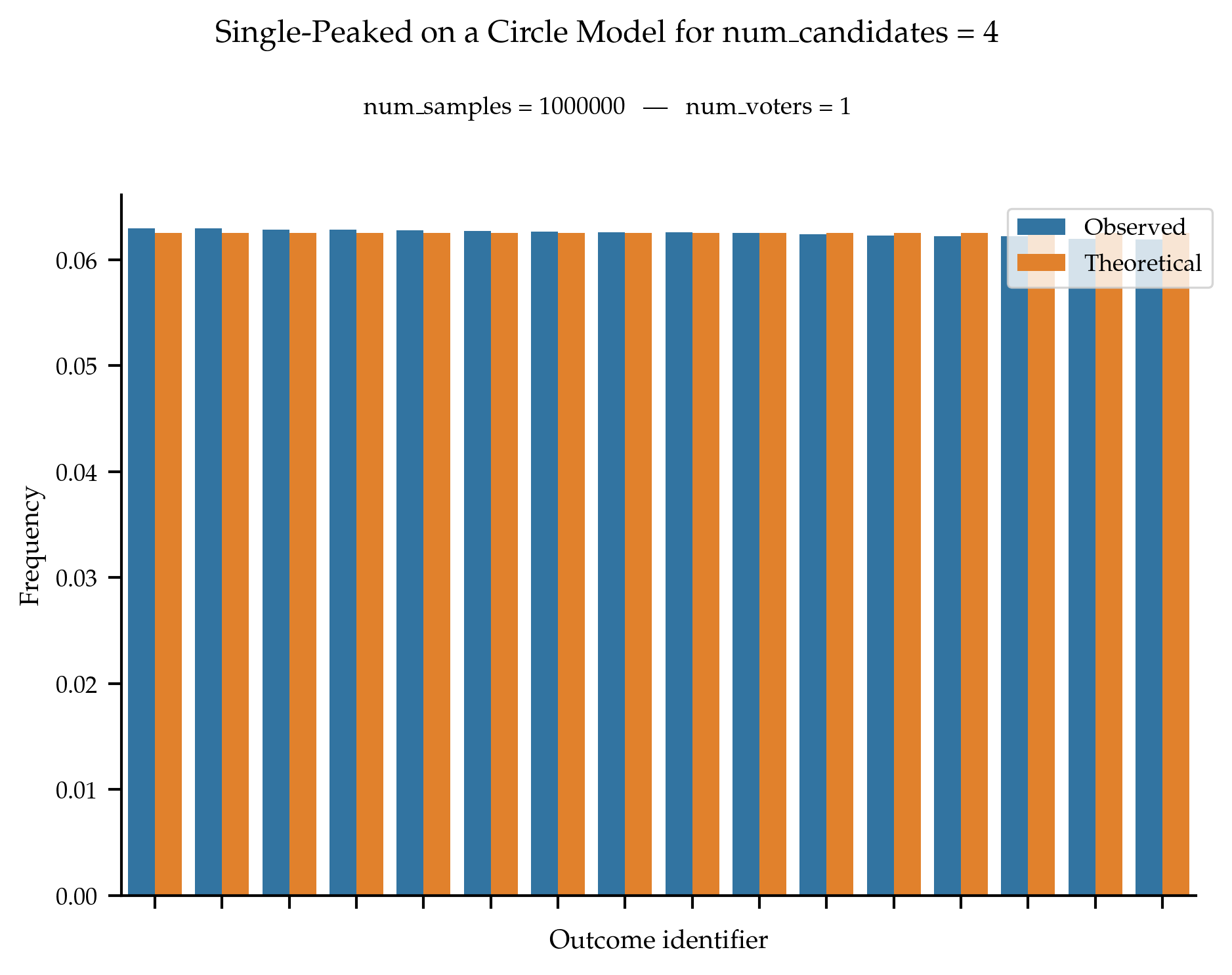
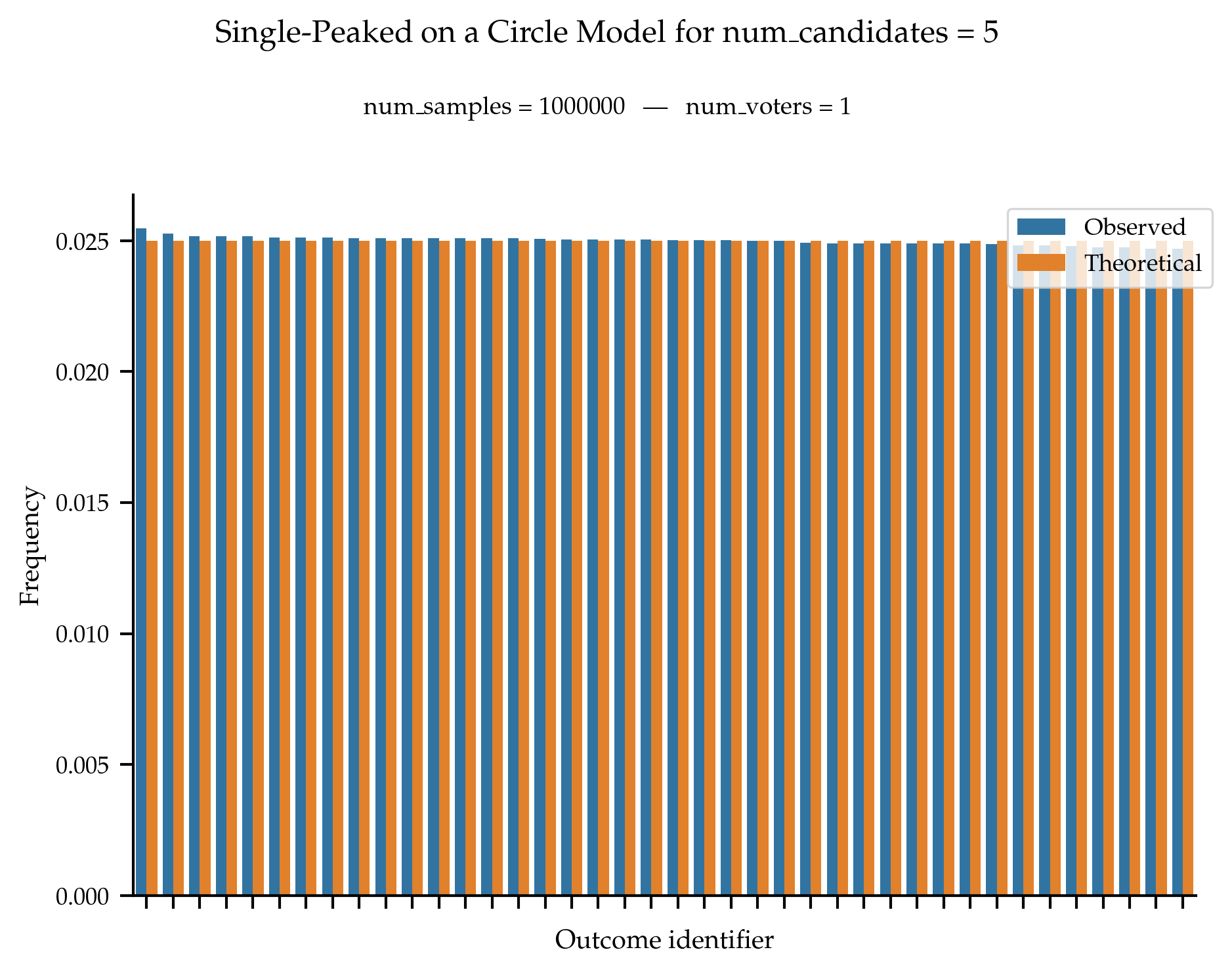
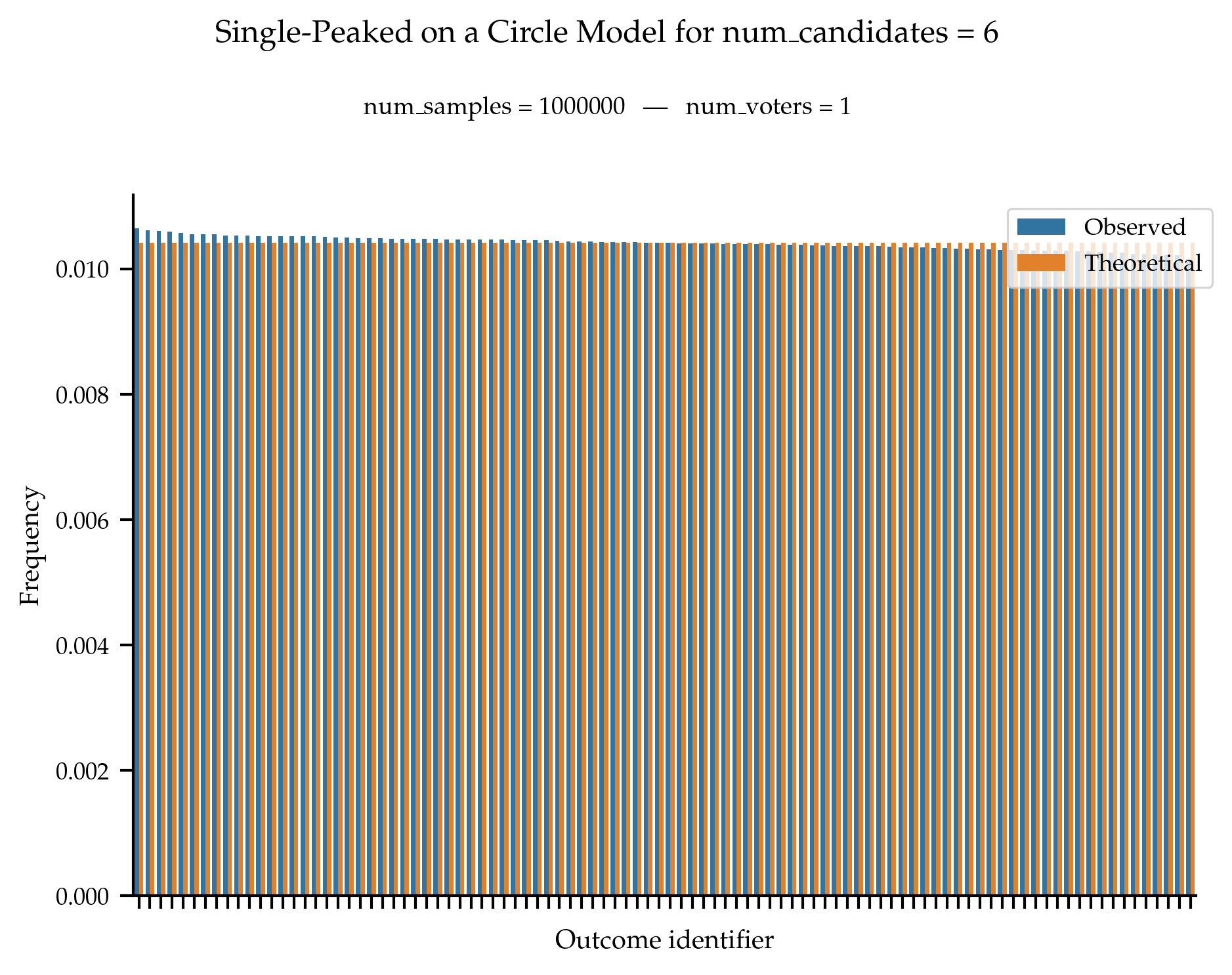
References
Preferences Single-Peaked on a Circle, Dominik Peters and Martin Lackner, Journal of Artificial Intelligence Research, 68:463–502, 2020.
- k_axes_single_peaked(num_voters: int, num_candidates: int, k: int, axes_weights: float | Iterable[float], inner_sp_sampler: Callable = None, seed: int = None) list[list[int]][source]#
Generates ordinal votes that are single-peaked on k axes, i.e., a set of votes for which there exists k axes such that each vote is single-peaked on one of the k axes.
The sampler works as follows: k distinct axes are sampled uniformly at random. We ensure here that no axis or reversed axis is sampled more than one. Then, to sample a given vote, an axis is selected uniformly at random based on the weight distribution over the axes, and a single-peaked vote on this axis is sampled.
A collection of num_voters vote is generated independently and identically following the process described above.
Note that the resulting collection of votes can be single-peaked on less than k axes, and not exactly k, since a given vote may be single on several axes. It is also not certain that at least one vote will be sampled according to each axis.
- Parameters:
num_voters (int) – Number of Voters.
num_candidates (int) – Number of Candidates.
k (int) – Number of axes
axes_weights (float | Iterable[float]) – Weight of each axis. If a single value is given, all axes have the same weight, otherwise one weight needs to be provided per axis.
inner_sp_sampler (Callable, default:
single_peaked_walsh()) – Sampler used to generate single-peaked votes. This function needs to accept a name argument “axis”.seed (int, default:
None) – Seed for numpy random number generator.
- Returns:
Ordinal votes.
- Return type:
list[list[int]]
Examples
from prefsampling.ordinal import k_axes_single_peaked # Sample a 2-axes single-peaked profile with 2 voters and 3 candidates, # each axis with equal weight. k_axes_single_peaked(2, 3, 2, 0.5) # You can change the inner sampler from prefsampling.ordinal import single_peaked_conitzer k_axes_single_peaked(2, 3, 2, 0.5, inner_sp_sampler=single_peaked_conitzer) # You can given different weights k_axes_single_peaked(2, 3, 2, [0.2, 0.4]) # For reproducibility, you can set the seed. k_axes_single_peaked(2, 3, 2, 0.5, seed=1002)
Validation
None
References
None